Databases describe what is. Constraint solvers and optimisers decide what should be. Business decisions involve both — “which production batch should we make, given the recipes, and inventory we have?” — and today they require two languages, two execution models, and a pipeline between them. The database optimiser sees half the problem; the solver sees the other half; neither sees the whole.
My PhD work, with Luke Mathieson and Fahimeh Ramezani at UTS, is an early-stage attempt to close this gap from the foundations. After working through fifty years of related attempts — constraint databases, package queries, SolveDB, CombSQL+, and others — I’ve come to the view that three theoretical moves, taken together, unlock the unification.
Move 1: Complete domain relations. (CDR) Relational algebra (RA) so far has been about relations whose tuples are listed explicitly, with everything outside the listing implicitly absent. To distinguish these, we call them active domain relations. Constraint and optimisation problems need the opposite stance — a relation where everything in the domain is in unless excluded, defined by a characteristic function rather than an extension. We add these to RA as complete domain relations. Active domain relations, it turns out, occupy a finite region in the space of all CDRs: the active-domain fragment remains domain-independent, and algebraic operations close over it.
Move 2: Exponentiation, and a higher-order algebra. Relational algebra already has union (a kind of addition) and Cartesian product (a kind of multiplication). The third arithmetic operation — exponentiation — has been missing. Once relations can be defined by characteristic functions, exponentiation becomes available: it constructs search spaces as f : Data → Decision, the set of all functions from a finite data relation to a (possibly infinite) decision relation. The result is a set of relations rather than a set of tuples. We call these solution sets, and the algebra over them is higher-order — which is what lets a single query express both the data-transformation and decision parts of a problem within one algebra.
Move 3: A translation Φ, and reuniting results with structure. The higher-order algebra is given semantics by a homomorphic translation Φ that lowers solution-set queries into ordinary RA for evaluation. After evaluation, the returned values are reunited with the original problem structure — data attributes recombined with their corresponding decision values — so what the user receives is a relation in the shape they wrote the query against. The round trip is invisible at the query level.
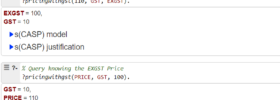
What this lets you write. Here’s the smallest query that exercises all three moves, in a polymorphic SQL where the same clauses span data, decisions, and search:
WITH ProfitableBatch AS (
SELECT * FROM SolutionSet(Cakes, Qty) B
WHERE ALL (SELECT sum(qty * amount) <= min(avail)
FROM B NATURAL JOIN Recipe NATURAL JOIN Inventory
GROUP BY ingredient)
ORDER BY (SELECT sum(qty * price) FROM B) DESC
LIMIT 1)
SELECT cake, qty, qty * price AS profit FROM ProfitableBatch;
Cakes, Recipe, and Inventory are ordinary tables. Qty is the decision relation — containing a single attribute qty – an integer 0..100 defined by a rule rather than enumerated. SolutionSet(Cakes, Qty) is the search space: all functions from Cakes to Qty. The query asks: of all batches the inventory can support, which maximises profit? Today this requires shipping data out to MiniZinc or Gurobi and back, with no shared optimiser across the join-aggregate part and the search part.
Where this is going. The payoff is one query, in one algebra, with evaluation that can draw on whichever algorithmic tradition fits the problem — set-based, constraint-solving, or a mix — without the user seeing the seams. The paper develops the formal framework; the next stage is a query compiler that takes the round trip end-to-end.
The full paper is on arXiv: arxiv.org/abs/2509.06439.
I’ll be at SIGMOD/PODS 2026 in Bengaluru and would love to talk to anyone with an interest in this territory — database theory, constraint programming, optimisation, or the bridge between them. If you’d like to grab a coffee, find me on the conference Whova app or LinkedIn .
— David Pratten, UTS