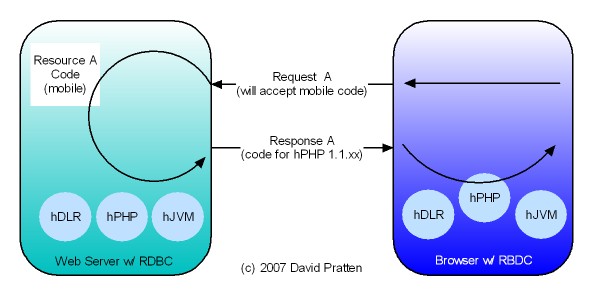
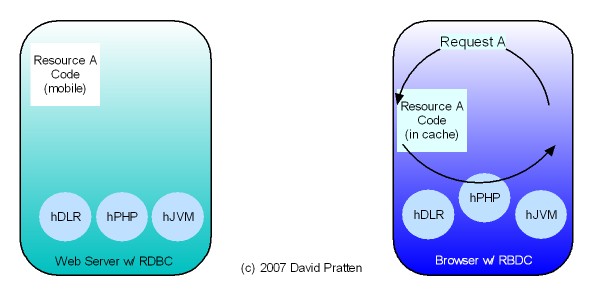
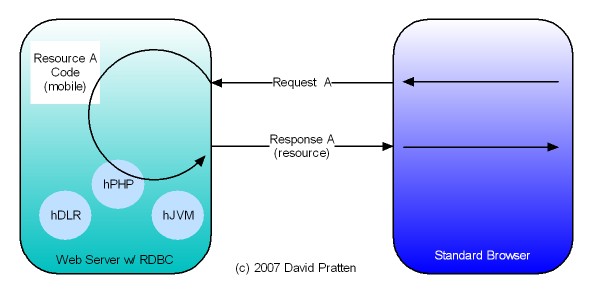
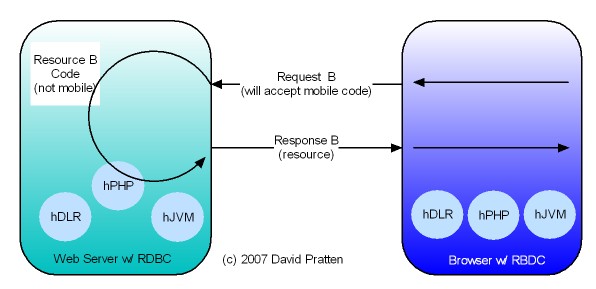
Opera has just released Opera Unite web server in the browser technology. Here is analysis by Mashable. Opera Unite is an enabling technology for tier agnostic Request Based Distributed Computing (RBDC). Key issues directly addressed by Opera Unite include:
Drivers
- Build Distributed Applications
- Provide programmers with a unified programming model (i.e. not deal with a separate programming model on the client)
- Build Mult-tier applications
- Use existing technologies
- Enable applications to ‘run anywhere’
- Provide a Language agnostic mechanism
- Use a Client agnostic approach
Conclusion
Reading the Opera Unite announcement has confirmed that the building blocks of RDBC are coming into being.