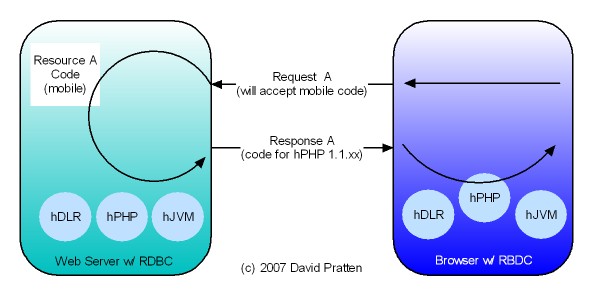
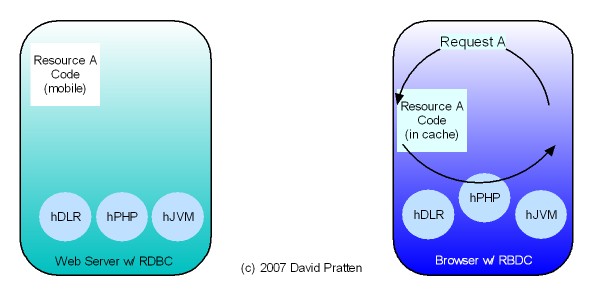
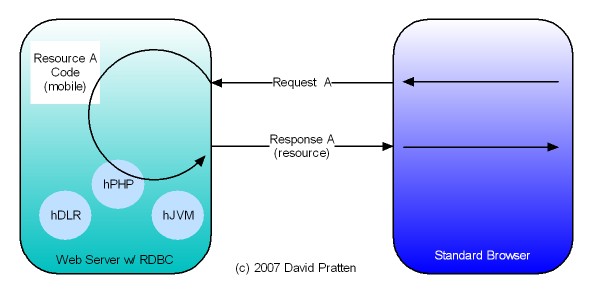
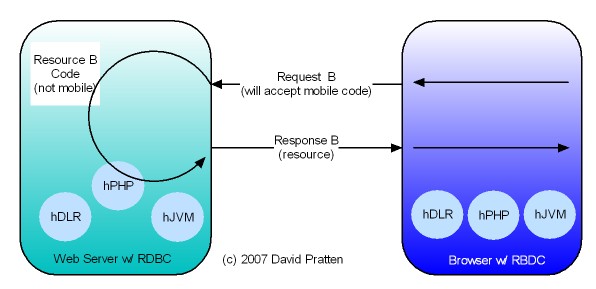
Tier-Agnostic requests are being used by the Wadi project in Java Server Farms. This Java-specific implementation lends support to the general applicability of Request Based Distributed Computing (RBDC) for client centric distributed computing.
WADI is an acronym of ‘WADI Application Distribution Infrastructure’. WADI started life as a solution to the problems surrounding the distribution of state in clustered web tiers. It has evolved into a more generalised distributed state and service framework.
The Wadi Docs describe an Invocation mechanism that shares features with RBDC. The Invocation Interface is a tier-agnostic encapsulation of a remote call. Here is a first-cut comparison:
Similarities
- Both use the idea of Tier-Agnostic Requests
- They have similar session-state mechanisms. See here for one proposal about state within RBDC.
- Both delay location of computing decisions until run-time.
Differences
- Wadi is targeted for use within a server farm, where as RBDC is proposed as starting in the client and works into the server farm with the same mechanism.
- Wadi maintains centralised knowledge of the location of active Java objects whereas RBDC works as an extension of http’s native request by request invocation pattern.
- Wadi is programmed specifically for Java, RBDC is proposed as a generic mechansim.
- Wadi is visible to the Java programmer. RBDC is proposed as a generic mechanism that could become as ubiquitous and ‘invisible’ as http requests are today.
In summary, the usage of Wadi in the server farm, serves as a pointer to the potential of RBDC in the client and server.